晚上正在正常用网,突然全断了。
进 OpenWrt 后台一看,CPU 直接顶到 99%。再看活动连接数,更离谱:65535 / 65535
内核日志也在刷同一句:
nf_conntrack: nf_conntrack: table full, dropping packet
这是连接表被塞满了,内核开始丢包,新连接进不来,重启,几分钟后又满。拔电源晾半个钟头再插,还是几分钟后满。最后把 PassWall 总开关一关,CPU 立刻下去,conntrack 掉回一千多。
经过和claude的联合分析,这次故障的是 PassWall 一开,某个链路就在疯狂制造连接。
先确认是不是 PassWall 背锅
关着 PassWall 时,路由器状态很干净:
conntrack: 1611 / 65535
load: 0.03只要一开 PassWall,几分钟后连接表就冲到上限,日志开始 table full。关掉 PassWall,连接数又正常回落。所以问题不在普通 LAN 设备。故障点基本锁在 PassWall 这套代理和 DNS 链路里。
conntrack 为什么会被灌满
我这台路由器的 DNS 链路比较绕:
dnsmasq先接收局域网 DNS 查询- PassWall 用 nftables 把 53 端口劫持到自己的
11400 - 再交给
chinadns-ng分国内外 - 国内 DNS 走一个 AdGuardHome
- 国外 DNS 再绕到另一个跑在 Docker 里的 AdGuardHome,容器 IP 是
172.17.0.4
这个 Docker 容器 IP 后面很关键。172.17.0.4 在 PassWall 眼里属于内网段,因为 psw_lan 里包含 172.16.0.0/12。也就是说,它发出的 53 端口 DNS 查询,同样可能被 PassWall 当作 LAN DNS 流量劫回入口。
问题出在国外那个 Docker AdGuardHome 的上游配置
upstream_dns:
- https://1.1.1.1/dns-query
- https://1.0.0.1/dns-query
- tls://1.1.1.1
- tls://1.0.0.1
- 1.1.1.1
- 1.0.0.1
- 8.8.4.4
- 8.8.8.8
upstream_mode: parallel前四个是 DoH / DoT,走 443 或 853,没问题。后四个是明文 DNS,走 53 端口,麻烦就在这里。
当 Docker 里的 AdGuardHome 去查 1.1.1.1:53 或 8.8.8.8:53 时,这些请求会被 PassWall 的 53 端口重定向规则重新拉回 11400,也就是整条 DNS 链的入口。于是链路开始绕圈:
Docker AGH 查 1.1.1.1:53
→ 被 PassWall 劫回 11400
→ chinadns-ng
→ trust-dns
→ 又回到 Docker AGH
→ 再查 1.1.1.1:53
→ 再被劫回去这就是一个 DNS 环路。更要命的是,AdGuardHome 还开了 parallel 模式,每次查询会同时打给多个上游。一个查询不是变成一个连接,而是裂成好几个连接。
UDP conntrack 又不会立刻消失,通常会存活几十秒到几分钟。只要新连接制造得比旧连接过期快,65535 这张表就迟早被填满。
明文 53 环路这件事我以前踩过一次,当时已经把国外 AdGuardHome 的上游改成只留 DoH / DoT。问题是,这次它又出现了,说明配置里那几条明文 DNS 后来又混回来了。
但更奇怪的是:既然环路条件一直在,为什么平时不炸,偏偏这天炸?原因是它平时被 DoH / DoT “压住了”。
在 parallel 模式下,AdGuardHome 会同时问多个上游。正常情况下,DoH / DoT 走代理隧道,结果很快回来。只要有一个上游先返回,其他还在路上的查询就会被取消,明文 53 那条环路来不及真正滚大。
但一旦代理隧道哑火,DoH / DoT 不再快速返回,明文 53 查询就没人收尾了。它们开始一圈一圈转,把 conntrack 表灌满。
所以这次不是单点故障,而是两个条件叠在一起:
- DNS 链里残留了明文 53 上游,具备环路条件
- 代理隧道突然不可用,让原本被压住的环路跑起来
那下一步自然要问:代理隧道为什么突然不可用?
基于AnyTLS协议的节点和基于ShadowSocks协议的节点
主节点是一个美国的 shadowsocks-2022 节点。我第一反应是节点挂了。毕竟 PassWall 连不上,DNS 又开始炸,很自然会怀疑服务器。但扫了一圈端口,可达性是通的。curl 返回 52 的意思是“TCP 连上了,但对方没有返回 HTTP 内容”。对代理端口来说,这基本可以说明端口不是死的。更关键的是,同一个美国节点,在手机上的 FLClash、电脑上的 Clash Verge 都能正常用。只有路由器上的 PassWall 连不上。
真正的问题是路由器时间
shadowsocks-2022 有防重放机制。客户端发起连接时会带时间戳,服务端会拿自己的时间去比。如果时间差太大,一般超过几十秒,就会被当成重放包丢掉。
也就是说,SS-2022 不只看密码、端口、加密方式,还很在意客户端的时间准不准。
我原本没往这个方向想,因为 OpenWrt 后台看起来时间是正常的。但后台显示的本地时间不代表 UTC 绝对时间一定准。于是 SSH 上去敲:
date -u再拿几个网站 HTTP 响应里的 Date 头对比:
路由器 date -u: 08:29:55 UTC
百度/腾讯/淘宝/京东/阿里 HTTP Date: 09:31:32 UTC路由器慢了一个小时多一点。
再跑 NTP 校时,offset 直接把真相写出来了:
ntpd: setting time to 2026-06-05 02:42:02 (offset +3697.462655s)3697 秒,大约 61.6 分钟。SS-2022 那几十秒的容忍窗口早就爆了。服务端自然会把 PassWall 发来的连接当成重放包扔掉。
这也解释了为什么 anytls 节点临时能用。TLS 证书的时间校验通常是按天、按年算,只要系统时间别离谱到证书有效期外,一小时误差不一定立刻致命。SS-2022 的时间戳窗口就严格得多。
手机和电脑没事也很好解释:它们的系统时间会自动同步,同一个节点在 Clash 里自然能连。
路由器为什么会慢一个小时
这台设备没有 RTC:
/dev/rtc 不存在没有 RTC 的路由器断电后记不住真实时间,开机只能靠 NTP 去对时。偏偏系统里 NTP 是关着的:
system.ntp.enabled=0所以它开机以后没有可靠校时来源,就一直带着错误时间跑。时间慢了,SS-2022 认证失败;代理隧道哑火;DNS 的 DoH / DoT 上游不能正常快速返回;残留的明文 53 上游开始绕圈;conntrack 表被填满;最后全网断。
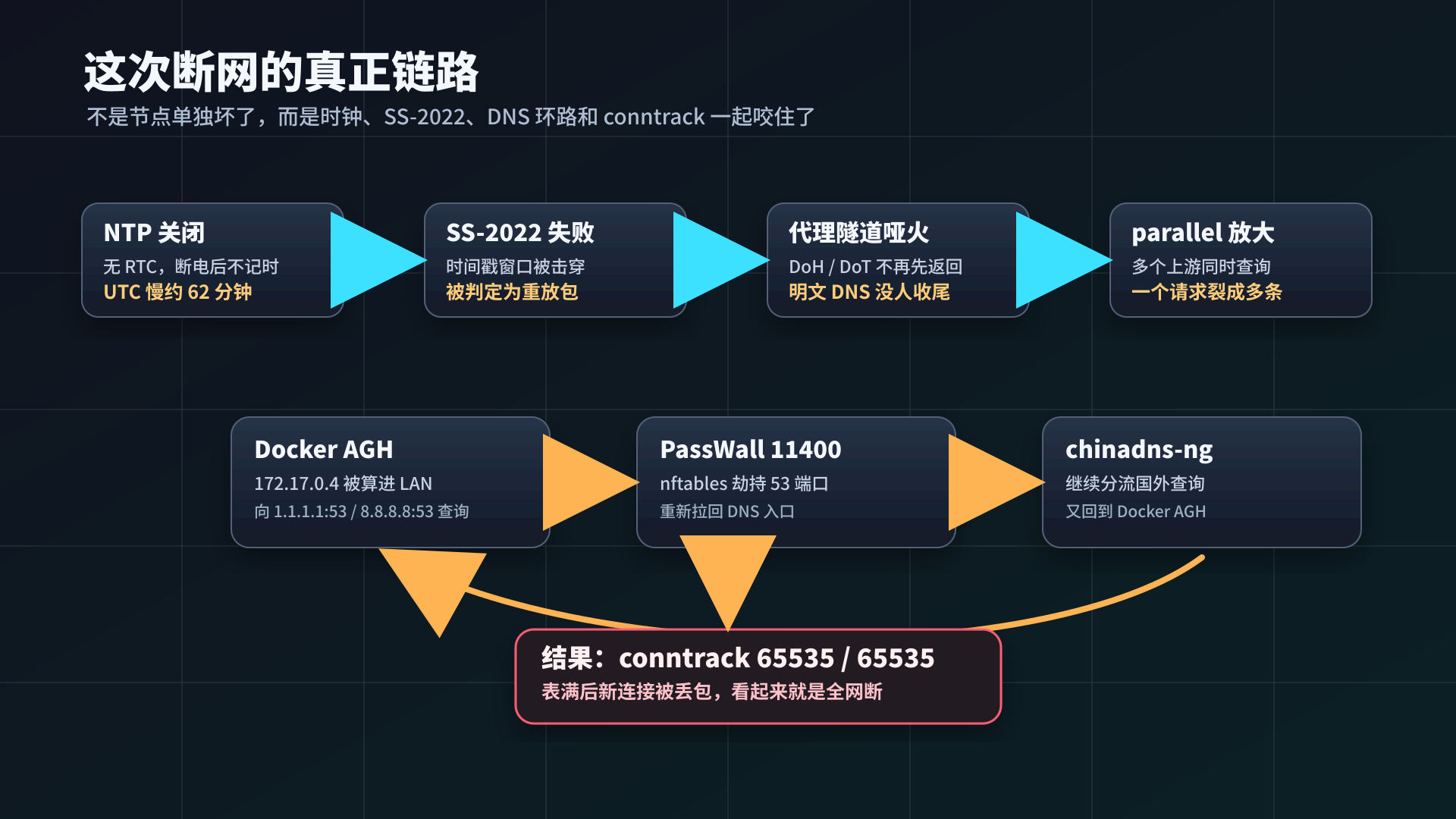
链路串起来就是这样:
NTP 关闭 + 无 RTC
→ 路由器 UTC 慢约 62 分钟
→ SS-2022 连接被服务端判定为重放
→ PassWall 代理隧道不可用
→ AdGuardHome parallel 模式下明文 DNS 查询没人收尾
→ Docker AGH 的 53 查询被 PassWall 劫回 11400
→ DNS 环路持续制造 UDP conntrack
→ nf_conntrack table full
→ 新连接被丢包,全网断到这里,“突然断网”也就说通了。不是上行断了,校园网日志里也没有真正掉线;是路由器自己的连接表满了,把新连接全丢了。
修复一:拆掉明文 DNS 环路
第一处修复,是把国外 AdGuardHome 上游里的明文 53 全删掉,只保留 DoH / DoT。
修完重启容器,再打开 PassWall 观察连接数。刚开的时候因为设备重连,conntrack 会有一波上冲,但很快回落:
conntrack: 4537 → 6039 → 3329 → 1243 → 1353
load: 0.03table full 没再出现。
这个修复很关键。因为它不只是解决这一次故障,还能防止以后任何节点异常时再次把整台路由器拖死。
以后代理节点就算挂了,顶多是国外 DNS 查不出来;不应该再因为 DNS 环路把 conntrack 填满,连国内连接都一起陪葬。
修复二:恢复 OpenWrt 自动校时
第二处修复,是重新打开 OpenWrt 的 sysntpd。
校园网有时会封 NTP 的 UDP 123,所以我先测了一下。阿里、腾讯、微软这些时间服务器能通,那就直接配置:
uci set system.ntp.enabled='1'
uci set system.ntp.use_dhcp='0'
uci -q delete system.ntp.server
uci add_list system.ntp.server='ntp.aliyun.com'
uci add_list system.ntp.server='ntp.tencent.com'
uci add_list system.ntp.server='time.windows.com'
uci add_list system.ntp.server='cn.pool.ntp.org'
uci commit system
/etc/init.d/sysntpd enable
/etc/init.d/sysntpd restart重新对时后,再和 HTTP Date 对一下:
router_utc=09:43:38
baidu=09:43:39这就对齐到秒级了。
因为这台路由器没有 RTC,重点不是手动校一次,而是让 sysntpd 开机自启。这样每次断电重启后,它都会自己找 NTP 对时。BusyBox 的 ntpd 会自适应轮询,开机几秒内同步,后面隔一段时间再核对,不需要手动配太多东西。
还有两个尾巴
第一个尾巴是 nf_conntrack_max。
我本来在 50-local.conf 里把它写到 262144,但实际被 /etc/sysctl.d/qca-nss-ecm.conf 里高通 NSS 那套配置压回了 65535。
不过这次我没有急着调大它。因为 conntrack 表只是结果,不是病根。环路还在的话,把上限从 6 万调到 26 万,最多只是晚几分钟炸,不能解决问题。
第二个尾巴是开机顺序。
无 RTC 的设备开机前一两分钟时间可能还是错的。如果 PassWall 比 NTP 先起来,SS-2022 节点可能短暂连不上。等时间同步后通常就恢复。
如果以后觉得这个等待很烦,可以加一个开机钩子:先等 NTP 同步,再启动 PassWall。我这次暂时没加,因为校时恢复后,实际影响已经不大。
下次遇到类似问题,先查这几个点
这次排障给我的经验很直接:
date -u以后如果再遇到“Clash 能用、PassWall 不能用”,尤其节点是 shadowsocks-2022,第一件事不是骂节点,而是先看路由器 UTC 时间准不准。
然后再看连接表:
conntrack -S
cat /proc/sys/net/netfilter/nf_conntrack_count
cat /proc/sys/net/netfilter/nf_conntrack_max如果日志里有:
nf_conntrack: table full, dropping packet就不要只想着调大 nf_conntrack_max。要先找谁在不停造连接,尤其要看 DNS 链里有没有 53 端口被反复劫持、Docker 容器网段有没有被算进 PassWall LAN、AdGuardHome 有没有在 parallel 模式下同时打明文 DNS 上游。
这次真正的故障不是某一条配置单独坏了,而是一串小问题正好咬在一起:
- 无 RTC
- NTP 关闭
- SS-2022 时间戳校验严格
- 代理隧道哑火
- AdGuardHome 残留明文 53 上游
- PassWall DNS 劫持规则把 Docker 容器请求又拉回入口
单看每一条都不算离谱,叠起来就足够把整台路由器打满。
折腾完以后,NTP 开着,时间对着,DNS 环也拆了。下次 PassWall 再“节点看着是好的,就是连不上”,我会先 SSH 上去敲 date -u
